
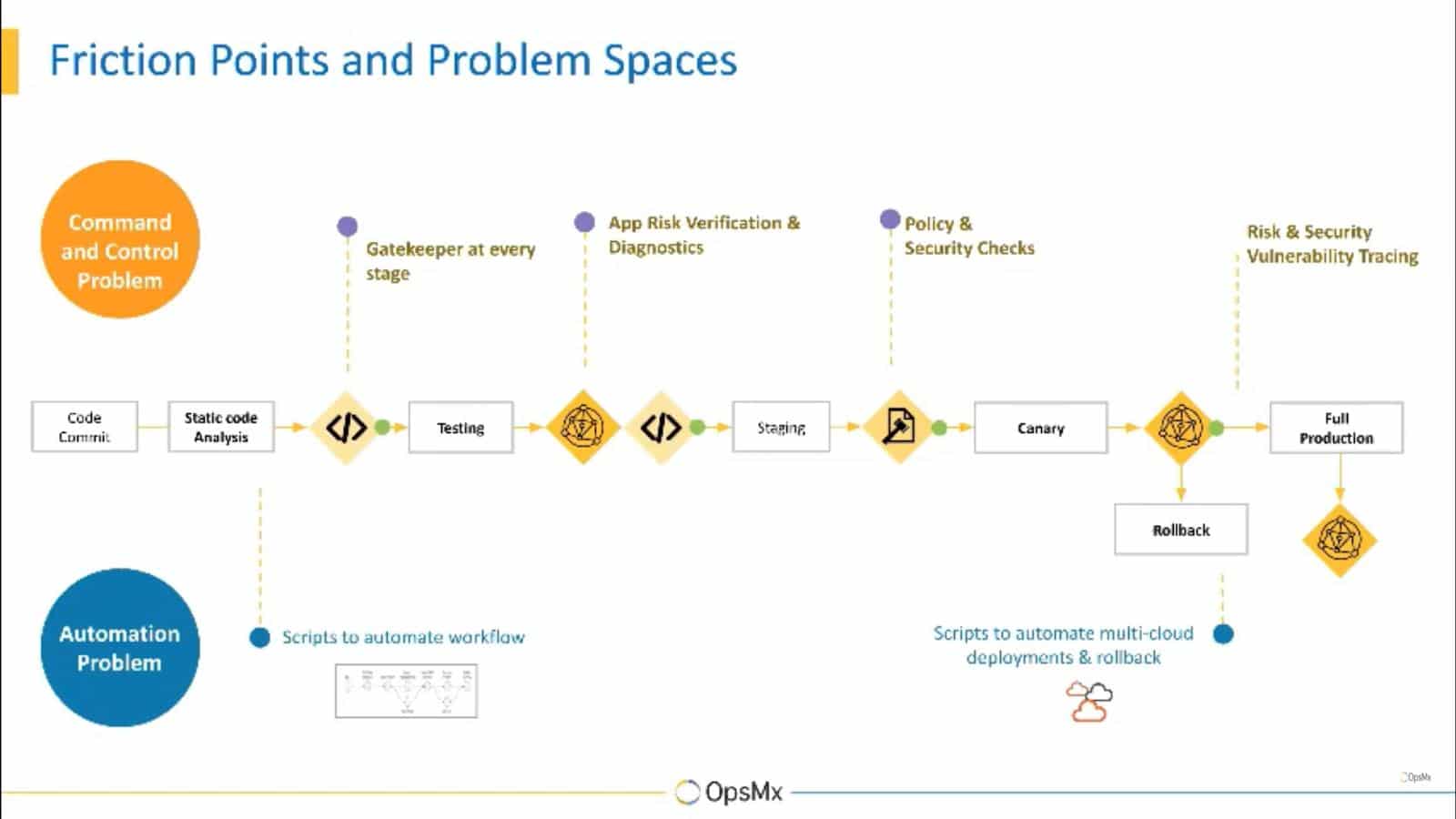
The majority of American companies today have adopted microservices architecture and implemented CI/CD processes to deliver software faster per their business demands. After interacting with hundreds of prospects in different industries, we have realized that DevOps teams often are dependent on experts to perform deployment and production verification of software before rolling out the new software to customers. The verification is usually done manually and is not enough when a vast amount of data must be understood, analyzed and critical decisions must be made.
For example, during canary deployments the operations team must analyze torrents of metrics and logs to decide if a canary release is fit for full production release. The most challenging part is it takes hours and is not scalable when multiple software are released per day. (A reference to a deployment pipeline and identifying where the maximum amount of time is consumed.)
The release verification is not limited to the deploy or production stage but is also done in the build and testing stage in order to detect the risk of a release early in the software delivery process. This is where one can use AI/ML in the CI/CD process.
Impact of Manual Verification on Business
With manual verification, your business will realize:
- Slow deployment velocity: When the verification is conducted manually, one would realize software wouldn’t go to production in a particular time frame, impeding the average deployment speed and frequency.
- Burdened SREs: With too many releases to verify, your SREs will burn out.
- High operating expenses: With more resources devoted to verifying applications and services, your project will add more operating expenses and lose focus on core development.
- Errors in production: One bad release is all it takes to ruin your reputation or stall business.
- Slower approvals: Without proper analysis, it becomes difficult for SREs to make roll forward or roll back canaries.
Applying Machine Learning to Your CI/CD Process
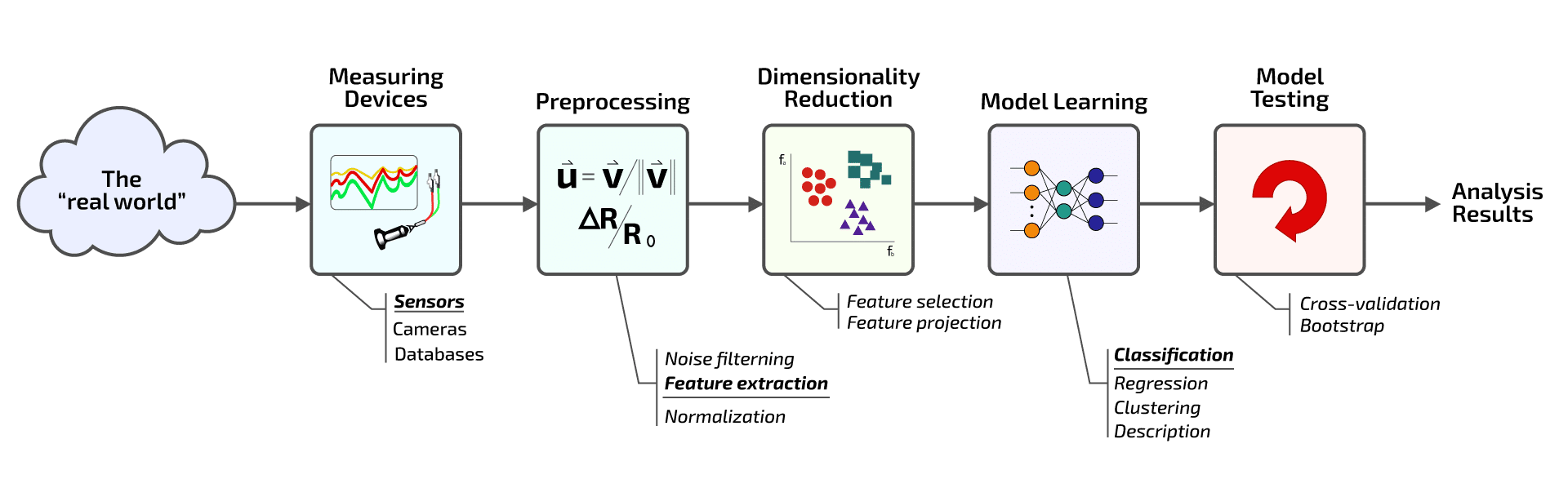
Data is at the heart of any ML algorithm. For CI/CD, it is the application logs and metrics (APM and Infrastructure). These data can be used to make deployment decisions faster and easier. It is essential to have quality data to make accurate predictions. Fortunately, data is emitted around the clock from different tools in the software delivery process, such as:
- Build logs: Jenkins, Travis CI
- Test Logs: Selenium, Apache Test Harness
- Performance Metrics: DataDog, Appdynamics, NewRelic, Prometheus
- Application logs: Splunk, Sumo Logic, Prometheus
- Infrastructure Metrics: Kubernetes
OpsMx offers Autopilot – an intelligence layer for software delivery — to leverage machine learning to large data sets, speed up verification and automatically reduce the risk of software release. Now SREs and DevOps teams can make intelligent inferences from the extensive data emitted 24/7 from the application with Autopilot.
At OpsMx, we have developed pre-built integration with 40+ different CI/CD tools chains so you can integrate and observe logs and metrics from them and make effective decisions. OpsMx Autopilot intelligently predicts and estimates possible build risks and alerts you in seconds. Autopilot can automatically verify a release in early-stages and identifies any regressions, anomalies, or failures that may have been introduced.
One of the use cases is to use ML for canary analysis. In this process, the canary (or a new release) is compared with the baseline version based on a selected list of metrics and logs to infer whether we will promote or roll back the new version. To learn more, please read What is Canary Analysis?
We will showcase how logs and metrics of canary can be fed into an intelligence system like OpsMx Autopilot to make predictions and estimations for faster decision-making in a delivery pipeline such as Spinnaker.

Use-case: Canary Analysis in Spinnaker using OpsMx Autopilot
OpsMx Autopilot uses customized parsing and clustering techniques for log analysis. Let us first understand how logs can be used for analysis using ML.
Machine logs are generated by every application in either a structured format (e.g., JSON, XML) or unstructured format. It isn’t straightforward to read and analyze unstructured logs.
These unstructured log messages are parsed into structured message templates and parameters to make it effective for grouping. After OpsMx parses the logs and puts them in a structured format, it uses the clustering techniques to group them together based on similarity. Based on certain predefined and custom rules, the severity of each cluster is set, which is then used to determine the risk associated with the canary. For example, in the image below, FileNotFoundException and IOException errors are grouped into different clusters with information presented individually for both.
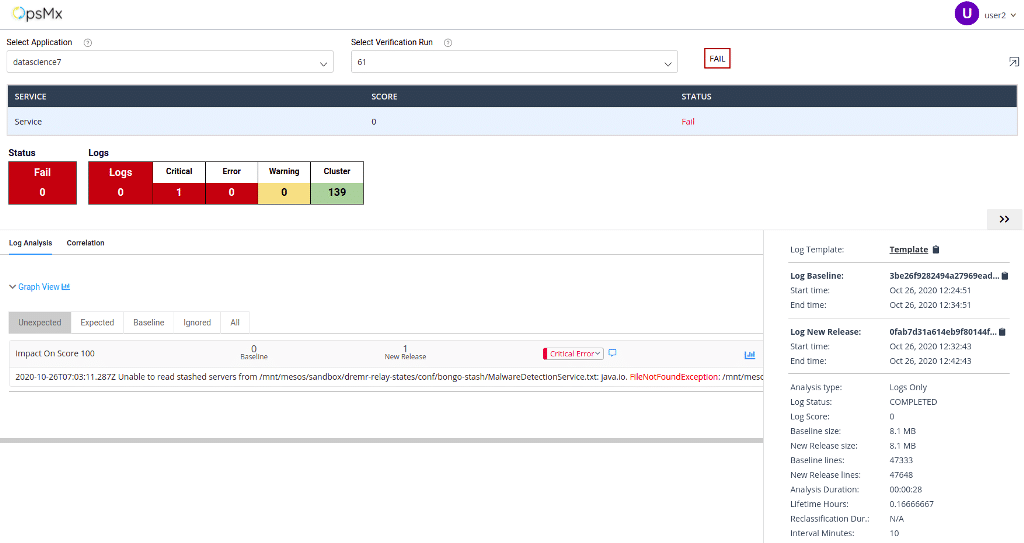
The best part is it does all the analysis in seconds. In the below example, Autopilot can analyze 7000+ logs of canary and baseline in 12 seconds.
Usually, customers or SREs have the independence to define if any token will be critical for the rollout decisions. After the clustering, OpsMx Autopilot’s scoring tool scores the canary on the basis criticality of errors, frequency of error occurrence, the similarity of errors occurring in the baseline and canary, etc. Once Autopilot provides a score of how good your canary is compared to the baseline, roll forward or roll back decisions can be made immediately.
OpsMx Autopilot Weight Modelling and Analysis for Metrics
There can be hundreds of different KPI metrics to an application. The first stage for any SRE is to identify which are the key metrics to determine the system’s health. It is tough to keep track of hundreds of KPIs so it is advisable to keep a watch on primary KPIs.
OpsMx Autopilot uses machine learning algorithms for weight modelling to provide the most critical KPI metrics. The importance is exhibited in the form of weights. A metric with higher weight is designated to be more important than a metric with lower weight. Since metrics are time-series, it is easy to visualize and process the data using several techniques. One simple way is to put a threshold to notify if a canary deviation from the baseline occurred by a certain percentage and, based on that, a canary can be rolled back. Other statistical-based techniques can be used along with the weights identified using a weight modelling method where a comparable score can be obtained.
Diagnosis and Triage Using OpsMx Autopilot
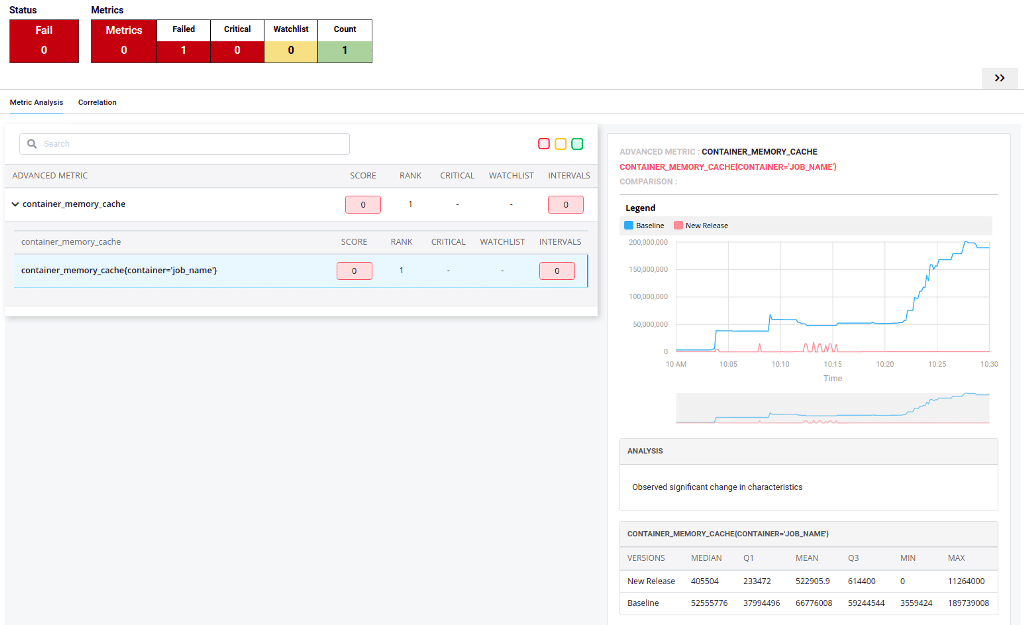
SREs used to spend half a day analyzing the root cause of production verification. However, with Autopilot, they can now save significant time. You can use statistical techniques to correlate two variables, in this case- logs-to-logs and metrics-to metrics, metrics-log E.g., anomalous behavior in Kubernetes container memory metrics, when correlated with records in the same period, can provide the root cause of analysis in human-readable form. (Refer to the image below.)
If you are interested, please watch the whole video:
Summary of Using AI/ML Algorithms for Automated Verification
Clearly AI/ML techniques such as natural language processing, transformer learning, clustering, pattern recognition, and time-series analysis can help SREs to accurately analyze data emitted from various CI/CD tools in seconds. The implementation of AI/ML speeds software verification and introduces scale in software delivery. The next step is automated decisioning to roll forward or roll back software in your delivery pipeline.
Want to try OpsMx Autopilot? Contact us for a 14-day trial..
If you are a Spinnaker user and want to improve visibility, control, and configuration management in Spinnaker, try OpsMx Autopilot Community Edition for free.
If you are interested in learning more about how Fortune 100 companies are leveraging AI/ML to speed up CI/CD.

0 Comments