
DevOps is like a three legged stool, because it is a balancing act between the three outcomes : Velocity, risk and quality. Any organization will expect these outcomes from its DevOps team.
Velocity:
This is the classic issue of getting code from the fingertips of your developers, out to the edge where it can start to add value to the business (customers/internal users). With the right tooling one would think this is easy to accomplish, however as you attempt to do this while balancing other priorities it can start to become more and more difficult. Below is a graphic from a Gartner study that illustrates this point:
Source: Gartner Study 2017
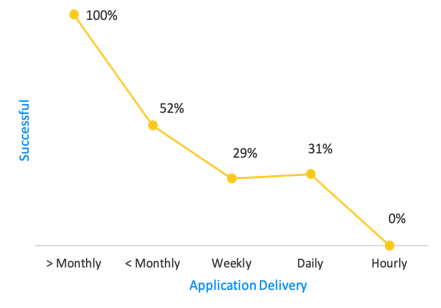
Gartner Study Report
As you can see the data suggests that the faster you attempt to deploy, the higher the risk of failure. Not only is this the result of the need to automated workflows, BUT also as you attempt to increase velocity while trying to address the other two legs of the stool you introduce opportunity for failure.
Risk:
The second leg of the stool is risk. Managing risk comes in several forms, let’s take a closer look at the the risks we need to be managing:
Compliance Risk: Is your industry regulated (SoX, PCI, ISO etc.)?
Security Risk: Has the code passed the needed surety risk, and does the deployment environment meet the needed security requirements?
Policy Risk: A close brother of Compliance risk that will focus on your internal and operational needs (things like blackout windows, verification and approval steps associated with a pipeline etc.)
Managing risk brings the second dimension to the Continuous Delivery Process and generally for most represents the largest of the challenges. The key is figuring out where you can safely automate to ensure you are managing risk effectively while not introducing more risk, and not impacting velocity. This is a challenge that is largely manual today, through the process of decision gates where a human needs to review a set of data and make a decision around if the candidate code moves from the current stage to the next stage in the process. Not only is this a manual part of the process, the data is typically spread out among different tools with no real “system of record”.
Managing risk is critical but you can see where it can run counter to our velocity goals, presenting us with the first large challenge in balancing ourselves on the three legged stool.
Quality:
The third log of the stool is quality. we have to keep in mind that while we are trying to move fast and stay within the risk parameters we have set out above… we need to make sure we deliver a quality product. We need to make sure we insulate our customers/users from any and all badness, plus having a fast assessment post deploy rollback plan should a problem be identified once the cde is released to production.
Quality will always start with testing, and the results of those tests (typically pass/fail). The problem space here is the pass/fail tests will not capture the anomalies that may be produced from a log and metrics perspective, a layer below the binary result of the testing. Many of us forgo this step because it is very labor intensive, or simply settle for metric monitoring and compare the results from the previous release. What we are NOT doing is combining logs AND metrics to help spot anomalies during the test or canary run… Why would we skip this step? We are risk averse people, however it comes back to having to serve the velocity master, and this process can be time consuming. BUT what if we were to automate this process, only surfacing the ominous log messages for review, saving us from having to search for the needle in a haystack?
By not executing on this step we are basically swallowing the risk of exposing badness to our customers or users, and the value of the software is lost to those who ran into the issues we missed. This also speaks to being able to make a decision to rollback once deployed if we are able to spot one of these issues soon after the production deployment, and initiate damage minimization should something slip through our net.
Again quality is not something we are able to compromise on, putting us in a tough spot… as it can impact our ability to operate at velocity if we don’t automate.
How should we attack this problem:
The issue can be summarized as balancing these three VERY important elements of the SDLC, and typically I am able to pick two of these things and execute (BTW but cutting steps out of the process you are essentially making that choice)… So how do I get to all three? Three words… Automation, Automation, and Automation…
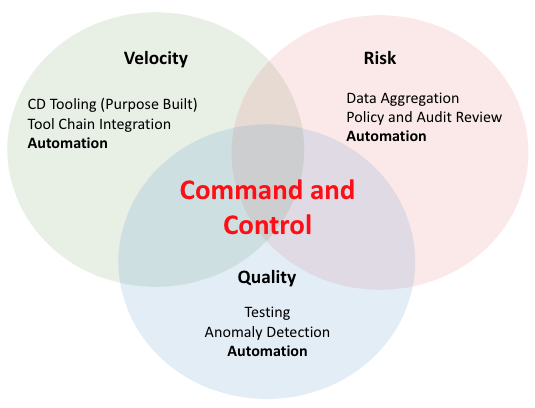
Command and Control
We need to examine our process, understand where the choke points are, and look to automate anything that we can:
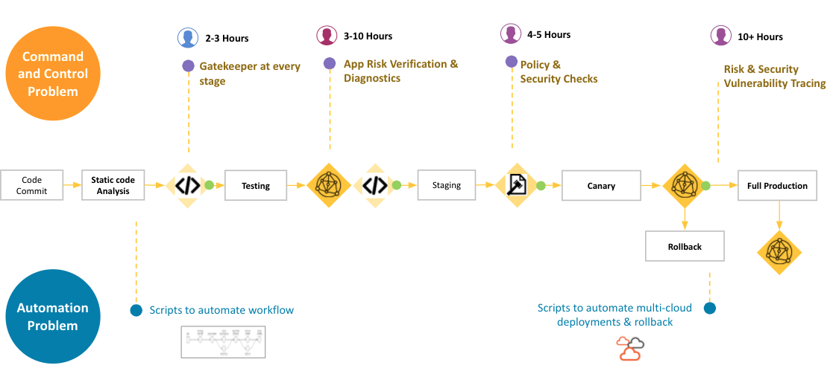
CICD Pipeline
As we review the choke points we start to realize as a first step we need to introduce a command and control layer, something that has DIRECT influence over the pipeline. Next we need to aggregate data (for evaluation and automation purposes), and third in order to automate where we can we have to have a way to evaluate the data collected against what is expected for a pass/fail (basically a run-time policy engine that will make the data driven decisions for us). Once we have these items in place we can start the process of automating the risk management decisions we talked about above.
In order to complete the process that will enable us to manage the quality of the software delivered, what we need is a system that will monitor the log and metric exhaust of our test runs, and/or our canary runs. This system should be capable of learning and being taught as it observes each run, and produce an assessment of the quality risk at each stage of the process (QA/Test, Staging, Production) at each stage prior to promotion we should be examining this data and using this data to build an abstract of confidence we have in this build by evaluating anomalies in the log and metric output. This process should extend to any post production deployment after set period of time allowing us to:
- Look for consistency in the anomaly detection (as the code moves from environment to environment).
- Make a fast and automated decision to roll back the code should a post deployment anomaly occur (prior to handing over to the mainline monitoring and APM tooling).
The velocity issue… well, this issue is solved through automated workflows and having a sound CD practice, using a tool that allow you to create a predictable and repeatable process based on triggers using he risk mitigation automation and the quality automation as guardrails that will help you balance the other two legs of the stool.
The Webinar will give you a chance to see how we at OpsMX think this problem can be solved. Using our AutoPilot command and control stack you can automate these management of all three legs of the CD stool and ensure you are creating a system of record and providing Audibility and Visibility to the process at the same time!
If you want to know more about Spinnaker or request a demonstration, please book a meeting with us.
OpsMx is a leading provider of Continuous Delivery solutions that help enterprises safely deliver software at scale and without any human intervention. We help engineering teams take the risk and manual effort out of releasing innovations at the speed of modern business. For additional information, contact us
0 Comments