
Highly available Spinnaker for scale
Today developers deploy applications continuously using a CD tool like Spinnaker. There can be many reasons such as cloud zone/region unavailability, due to which Spinnaker service can go down. With multiple teams working across multiple regions, Spinnaker downtime could impact the overall productivity and scale. It is very essential for platform engineering and SRE teams in an organisation to provide seamless developer experience with high availability Spinnaker.
Most zone-related failures can be handled by using the approaches suggested by the cloud provider. However, the region-wide failures will require additional steps to ensure high availability (HA). In this article we will explain the steps required to configure a multi-region Spinnaker and attain zero downtime even when an entire region goes down.
Implementing multi region Spinnaker for high availability
To implement HA Spinnaker, one can consider one of the two architecture mentioned below-
- Active-Active (AA): This involves running two instances of Spinnaker, both are active at the same time. The primary purpose of active-active architecture is to achieve load balancing, i.e. to distribute the requests coming from outside between the two instances. As there are two active instances, you can expect high throughput and response time of Spinnaker service. And also in case of a failover of one instance, the user will not observe the downtime of the service as the 2nd instance will still be continuing to serve.
- Active-Passive(AP): In this architecture, there can be two instances of Spinnaker, but there will be one active Spinnaker serving the requests and the other will be on standby. The passive Spinnaker instance will serve as the backup which will be ready to take over as soon as the active server fails due to the region going down. There can be a bit of downtime, very small time however, when the failover happens.
In this article we will provide the approach for implementing Active-Active Spinnaker architecture as it is a seamless transition of traffic and pipelines with no impact to users. Please note If you have implemented AA approach, it is easy to re-architect it to AP scenario using some manual/automated steps. However, there could be some downtime as the switch over happens.
Active-Active Spinnaker Architecture
We will briefly dive into the active-active architecture (refer Fig A) for Spinnaker HA. For Spinnaker microservices- deck(for UI) and gate (for api services), you will find cloud providers offering global load balancers (GLB) to direct traffic to the closest region. By configuring the GLB to the urls of Spinnaker deck and gate ingress in the two regions, we can direct traffic. Also one can configure a single ingress to access the gate as it is simpler. An alternative method is to use nodeport services for deck and gate services and configure the GLB to use the node public IPs as the endpoints.
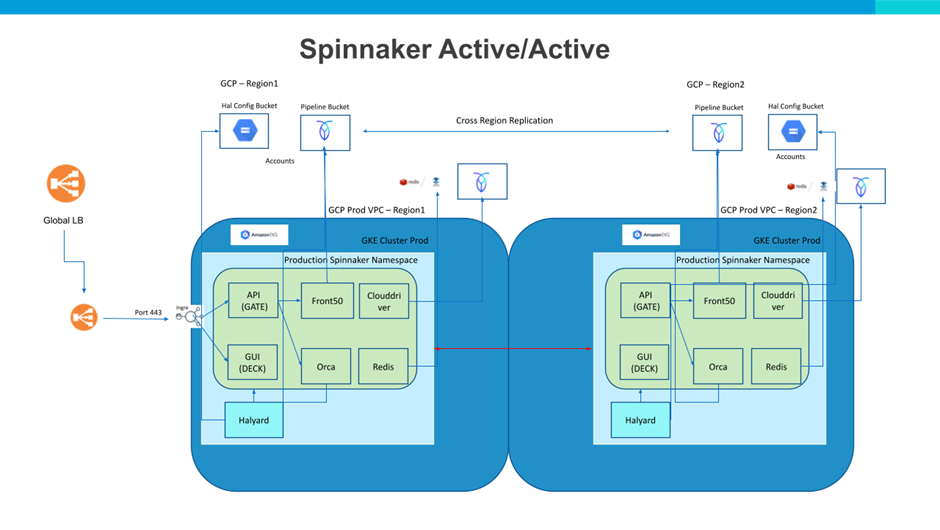
For database services (that has to be used between two Active Spinnaker instances), we have used Cockroach db (one can also use cloud provider mysql with cloud-provided replication across regions ), as it provides for multi-region synching of the replicas.
We have tried 3 approaches to enable the synching of the replicas across different regions.
- The first approach requires that the cluster DNS server be exposed as a load balancer and an entry of the other region be placed in the DNS server configuration of each region. This approach is susceptible to attacks in case the public IP of the DNS servers falls into wrong hands.
- The second approach is to create a peer connection between the two clusters. This requires the pod and services internal ip ranges do not overlap with those in the other region, so this needs to be set up at cluster creation time.
- The third approach is to use open source tool Skupper for multi cluster communication in Kubernetes. This requires setting up grpc connections between the clusters and requires running scupper related pods and services in both the clusters.
We recommended the peering approach for regions using the same cloud provider , and tested it using two and three regions in GKE. For regions using different cloud providers, it is better to use Skupper, which was tested with AKS, EKS and GKE clusters.
We also experimented with cross-region load balancing between Spinnaker services like orca and clouddriver using dummy service names pointing to nginx pods that direct traffic to local clusters and if no response then direct traffic to the remote cluster services. We found the strategy to be an overkill and not really necessary.
We also experimented with using Redis with Sentinel, to replicate Redis dbs and found this to be unnecessary as long as Redis is used for caches only. Local Redis caches were found to be the best way to go as they provided lower latency and do not need replication.
Next Steps
Configuring HA Spinnaker is the first step and may be a bit of hassle. Moreover it will also require to constantly monitor the service performance and health to initiate the failover (for Active-Passive). In case you want to get started with HA Spinnaker from Day-1, you can try OpsMx Enterprise for Spinnaker (OES).
References:
https://cloud.google.com/vpc/docs/using-vpc-peering
https://cloud.google.com/load-balancing/docs/https/setting-up-https
https://www.cockroachlabs.com/docs/v22.1/multiregion-overview
https://hackernoon.com/enabling-multi-cloud-kubernetes-communication-with-skupper-glz3u6p
https://blog.spinnaker.io/running-spinnaker-in-multiple-regions-at-netflix-7eefad1dde7a
0 Comments