
Site Reliability Engineering (SRE) is becoming a common term in software and Internet industries. Google Vice President of Engineering Ben Treynor Sloss, who coined the term, explained that “SRE is what happens when you ask a software engineer to design an operations team.” Since then, SRE has become a core component of the IT strategies of a variety of companies. Site reliability engineers (SREs) maintain networking and computing infrastructure, operating both with a focus on Quality Assurance and reliability.
The job duties of SREs span server infrastructure, applications, databases, networking, storage, mobile, unified communications, virtualization, and security firewalls. With such a vast scope of work, the specific job responsibilities can be unclear. Organizations may wonder whether they need an SRE practice. However, similar to the DevOps trends, SRE is now becoming a mainstream discipline. Let’s look into the role of site reliability engineers.
How SREs Add Value
The job responsibilities of SREs can be categorized into two buckets:
- Ensuring reliable IT systems and planning optimal infrastructure architectures to maximize an application’s ability to withstand vulnerabilities and failures. The goal is to maximize the resilience of the infrastructure.
- Responding to incidents during a crisis and implementing a strategic action plan to mitigate the incident.
- Ensuring reliable IT systems and planning optimal infrastructure architectures to maximize an application’s ability to withstand vulnerabilities and failures. The goal is to maximize the resilience of the infrastructure.
Their specific job responsibilities may include:
- Develop, test, and debug automated tasks (Apps, Systems, Infrastructure)
- Troubleshoot priority incidents, facilitate blameless post-mortems
- Work with development teams throughout the software lifecycle, ensuring sustainable software releases
- Perform analytics on previous incidents and usage patterns to better predict issues and take proactive actions
- Build and drive adoption for greater self-healing and resiliency patterns
- Lead and participate in performance tests to identify bottlenecks and opportunities for optimization, and forecast capacity demands
- Participate in 24/7 support coverage, as needed
This is not an exhaustive list and SREs adapt to new situations and problems. At the organization level, Site Reliability Engineering can be viewed as a megaproject. Organizations looking to reduce human toil can set up SRE teams to begin their journey and adopt best practices across the enterprise.
SRE vs. DevOps
DevOps is an organizational and cultural movement that aims to increase software delivery velocity, improve service reliability, and build shared ownership among software stakeholders.
https://www.opsmx.com/blog/comparison-between-site-reliability-engineering-sre-and-devops/
DevOps and SREs share many of the same principles:
- Increasing collaboration
- Learning from failures
- Focusing on team health and the happiness of customers
SREs provide concrete practices, vocabulary, and concepts that complement those of DevOps. For example, setting the right Service Level Agreement (SLAs), capacity planning, and developing failure mitigation strategies. DevOps and SREs reinforce and enable one another and use the principles and practices of each to improve performance continuously.
How SREs support in Software Delivery lifecycle.
There are many situations in which SREs can support their organizations during the software delivery lifecycle.
Balancing Reliability with New Features
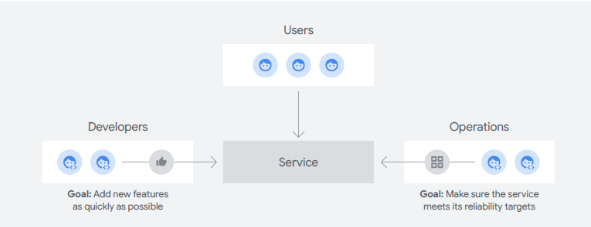
Organizations that need to add new features to a module that is essential to their customers face a difficult decision. On the one hand, operations and engineers do not want to risk failure and break the critical application by deploying a failed upgrade. On the other hand, developers are incentivized to push new features.
There needs to be a mechanism to support both teams and instill confidence in developers to push new features without a backlash from the operations team. The mechanism is SLAs. Each SLA defines a target – such as 99.5% uptime – for a service. Critically, SLAs are user-centric, based on something the service user cares about such as availability or latency.
Improving the Speed and Reliability of New Features
Organizations face a tradeoff between releasing new features rapidly and maintaining application stability and reliability. To match speed with reliability, SREs need to be involved in the design of the application. Developer and SRE collaboration can help manage the tradeoff between speed and reliability. With Site Reliability Engineering, organizations can move fast with much lower failure risks.
Reducing toil
“Toil” was coined by Google and had a crucial place in the world of DevOps and SRE. Toil refers to specific types of work needed to run a service. Work that qualifies as toil is manual, repetitive, and usually automatable. Most important, toil is work that does not provide any enduring value.
Toil is essentially a burden for staff and can increase the attrition rate of an organization. If a task can be automated, why not do so? This allows operations staff to devote their time to high-value work.
Identifying toil
Toil discovery can be a cumbersome process. People know what toil is but it is difficult to attribute to a process and much more challenging to quantify.
Consider a process that operations must restart every day to ensure it does not crash. It is a known issue among the operations team that if the process runs for more than a day, it crashes. This we can identify as toil.
To reduce toil, we can automatically restart this process every day using a cron job or a script. However, SREs can dig deeper with analytics to find the root cause of the repetitive failure. Finding the root cause requires some advanced knowledge that they can provide.
SRE for Enterprises
Companies with minimal IT footprint and do not have hundreds of transactions done every minute have begun relying on the cloud but not extensively. They don’t have substantial server farms or much computing power.
Most companies are now allocating budgets to adopt SRE, even if they don’t have issues that hamper their business reliability or stop them from scaling. We believe that the broad acceptance and recognition of the benefits of SRE is leading to change across organizations.
There is another reason we feel is driving organizations’ massive adoption of SRE. It is the reliability of industries on their digital footprint. Without a digital footprint, organizations cannot survive. Business leaders have high expectations from their websites and applications. But traditional IT strategy is not able to meet them. Even for companies running a mobile or an e-commerce application, they need to ensure that all searches must happen in milliseconds and that there is no delay in loading times. Slow loading times may increase the churn rate of customers. Hence SREs with a foothold in modern architecture design and concepts can lead companies to a brighter future.
Can Operations play the role of SRE?
Is operations no longer a separate entity? They must get involved in the application design and architecture process. For example, infrastructure as code. Operations have a good understanding of infrastructure, so they configure the computing environment for the application. SRE is another step further in that direction. SRE helps put operations on par with developers. Embracing SRE doesn’t mean organizations must hire a new set of operations people. It is all about eliminating toil and helping people grow.
Organizations setting up their first SRE team tend to take a kitchen sink approach where the designated team now has to set up new processes and SLOs when required. When such standards and processes and SLOs are agreed upon by the development and application teams, the organization can look further to expand the SRE team.
Have SREs crossed the chasm?
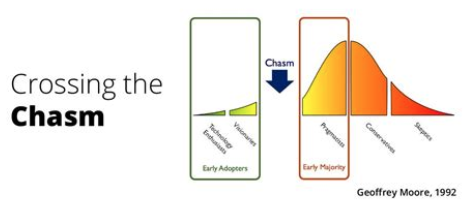
The theory of crossing the chasm is attributed to Geoffrey Moore, author of the book “Crossing the Chasm”. In the context of SRE, the chasm here refers to the gap between early adopters and the early majority of SRE adopters. Visionaries represent a small set of the overall market who have the capability and resources to adapt and test SRE effectiveness. In contrast, the early majority or the pragmatists wait for technology to prove valuable and beneficial. This group is sometimes referred to as a tornado because the market rushed to implement the new technology. Once a technology has begun adoption by the pragmatists, it has crossed the chasm.
We believe SRE is crossing the chasm, or it will have by the time you read it. Organizations that have begun investing in setting up SRE have started realizing value and adoption are rising exponentially. Even large organizations have implemented SRE enterprise-wide, and smaller organizations with varied digital footprints have also begun investing in SRE.
Conclusion: The Future of SRE
And, looking to the future, it appears the SRE practice will only continue to gain adoption as a method to support high availability and reliability and improve digital customer experiences. The SRE approach is also essential to meet service-level agreements (SLAs) and internal service-level objectives (SLOs).
0 Comments