
Table of Contents
Introduction to Kubernetes
If you want to understand the current buzzword “Kubernetes” and be able to communicate better with engineers and developers, you are in the right place. This blog will explain the basics of Kubernetes and why it is so important for modern deployment practices.
Before taking the plunge into the world of Kubernetes, let us understand what are containers.
What are containers?
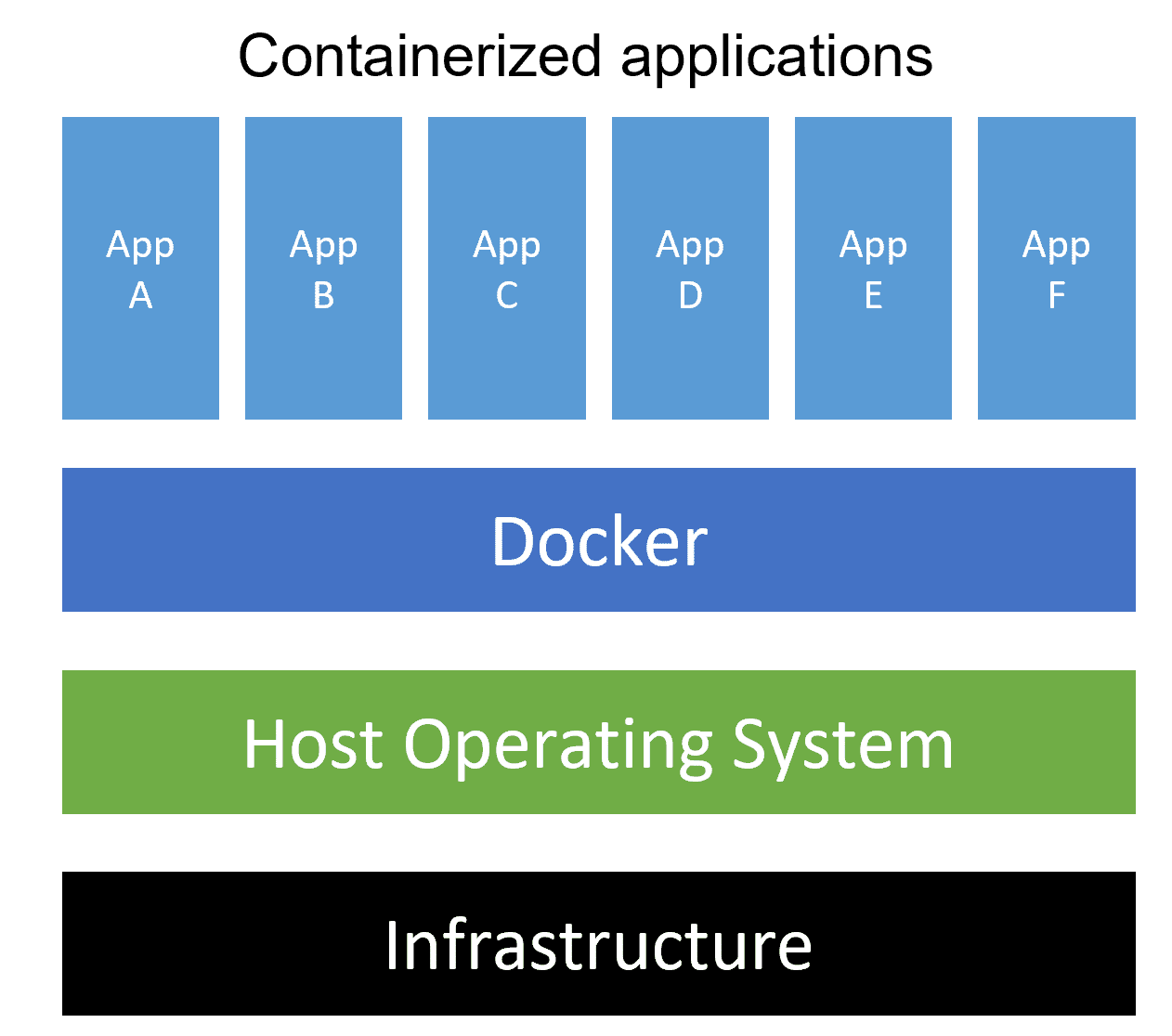
Containers are a form of operating system virtualization. A single container can run a small microservice or process for a different application. The Container will have all the necessary executables, binary codes, libraries, and configuration files. Containers are not to be confused with VMs. Each individual VM will have an OS, but a container does not. Therefore, containers are lightweight and organizations use containers in tens of thousands. Docker is one of the most frequently used container platforms.
Benefits of using containers over monoliths
- Reduced overhead costs.
Containers are light. They need fewer system resources than traditional or hardware virtual machine environments. This is because containers don’t have an OS of their own. - Improved agility.
Container architecture virtualization allows apps running on these containers to be deployed easily to multiple different operating systems and hardware platforms. - Dependency issues are a thing of the past.
Containers relieve DevOps engineers from worrying about the dependencies of their applications wherever they are deployed. This ensures a smooth transition from a testing environment to a production environment. - Greater efficiency.
Containers allow applications to be more rapidly deployed, patched, or scaled. - Better application development.
Containers support agile and DevOps efforts to accelerate development, test, and production cycles.
- Reduced overhead costs.
What is Kubernetes?
Kubernetes is a container orchestration framework that was developed by Google to manage docker containers. Kubernetes helps to manage applications that are running on hundreds or thousands of container environments. It can also manage applications running in different environments, like physical machines, virtual machines, or even hybrid deployment environments.
One of the most popular tools for this purpose is Kubernetes, a container orchestrator that recognizes multiple container runtime environments, including Docker. Kubernetes provides some edge functions, such as Load Balancer, Service discovery, and Role-Based Access Control(RBAC). Sometimes in the industry, Kubernetes is also known as “K8s”.

Why was there a need for Kubernetes?
Monolith systems pose many challenges in hosting modern applications. The rise of microservices architecture overshadowed the use of monoliths. With the use of microservices as the primary architecture, container technologies provided the perfect host for small independent applications, referred to as microservices. But as applications grew big, and the containers rose to the order of thousands, managing using scripts became really complex. As everyone was using their own custom scripts to manage these microservices, it became nearly impossible to create a standard process for managing them.
This created a need for container orchestration tools like Kubernetes.
What does a container orchestration tool (Kubernetes) offer?:
1. High availability / Zero downtime
Scripts can be sometimes a harrowing experience if there are hundreds of containers and something malfunctions. It becomes a momentous task to troubleshoot issues. Kubernetes ensures this does not happen by making containers accessible. We achieve this by quickly replicating a microservice that has failed.
2. Scalability
Managing containers manually means that the application will never reach its full potential. Kubernetes enables applications to run at maximum capacity, ensuring the highest performance. The fast performance will improve the response time of users accessing the application.
3. Disaster Recovery
Triage of issues in a manually managed container environment is like finding a book in a library without a sorting arrangement. So when disaster strikes a microservices environment running on custom scripts, data will be lost and services will go bust. The restore the services to previously stable state configurations and data has to be restored from a backup after rooting out the problematic container or configuration. Kubernetes inherently has the mechanism to back up the data and restore the application so that no data is lost.
Fundamental components of Kubernetes
Kubernetes has tons of components, but most of the time we will use only a handful of them. We will understand the role of these components and how they help in deployments.
1. Node and Pod
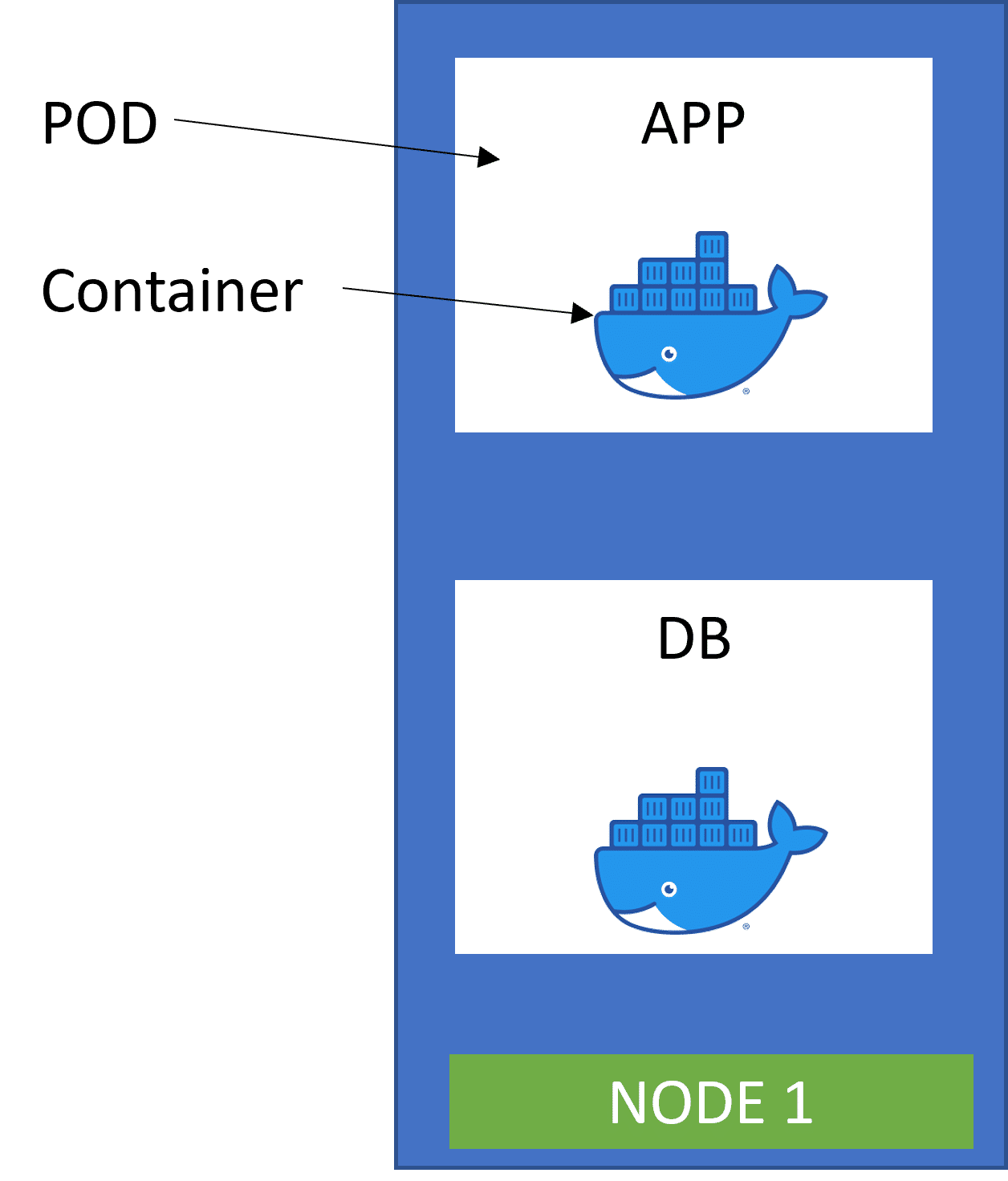
A node (worker node) in Kubernetes terms is a simple server, either physical or virtual machine. The smallest unit and the basic building block/component of Kubernetes is called Pod.
A Pod is an abstraction over a container. Pod creates a running environment on top of a container. This allows Kubernetes to replace the pods wherever necessary without the need to interact with docker or any other compatible container technology. The concept is to run on an application/service in one pod.
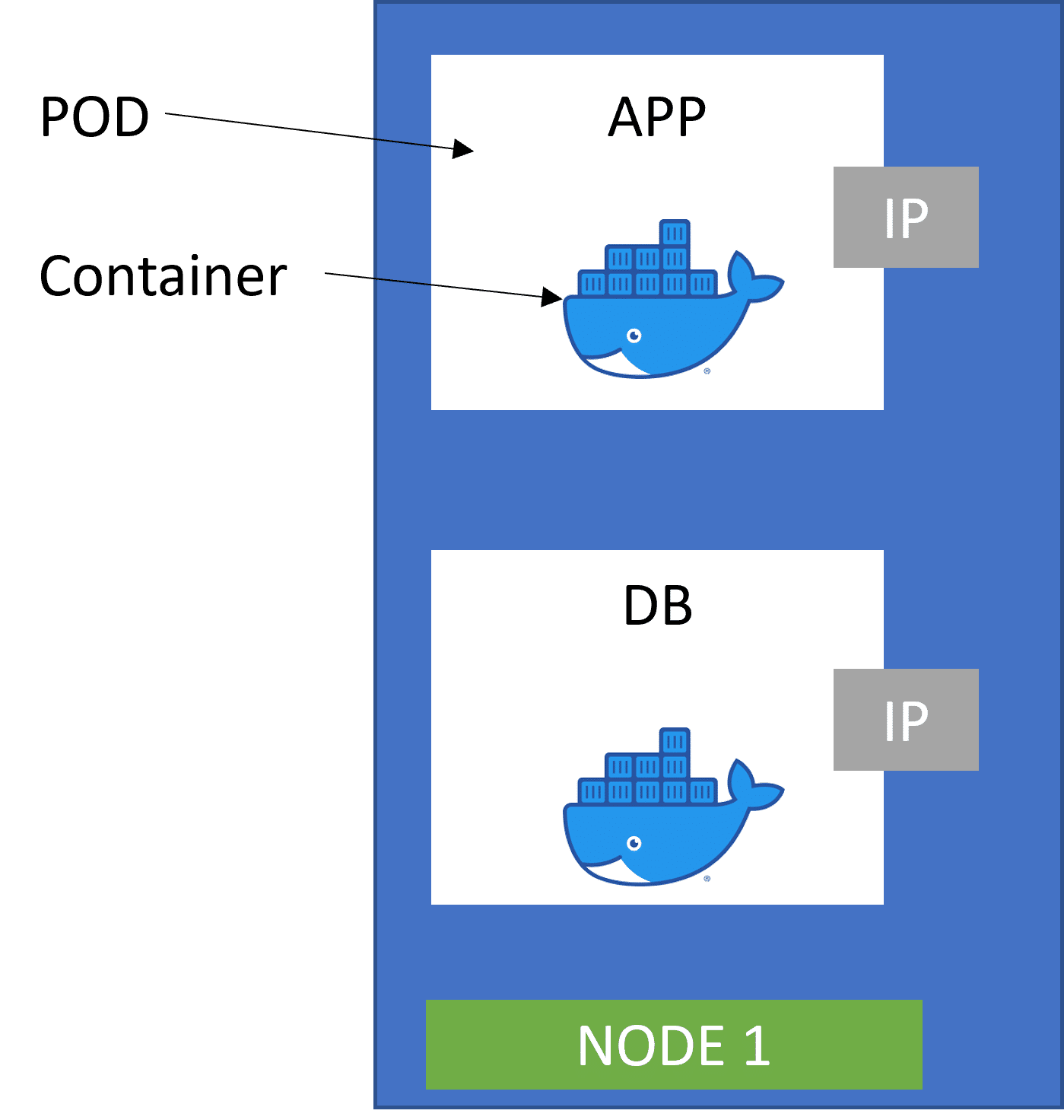
Next, we understand how they communicate. Kubernetes offers out-of-the-box support for virtual networks, which enables pods to communicate with each other using private IPs. But these IPs are constantly recycled because of events such as pod failures.
In case of a pod failure, Kubernetes will create a duplicate pod to ensure continuity and assign a new IP for communication. As this will be a new IP, other services might fail to communicate. This is resolved using the service that will quickly resolve communications to the new IP.
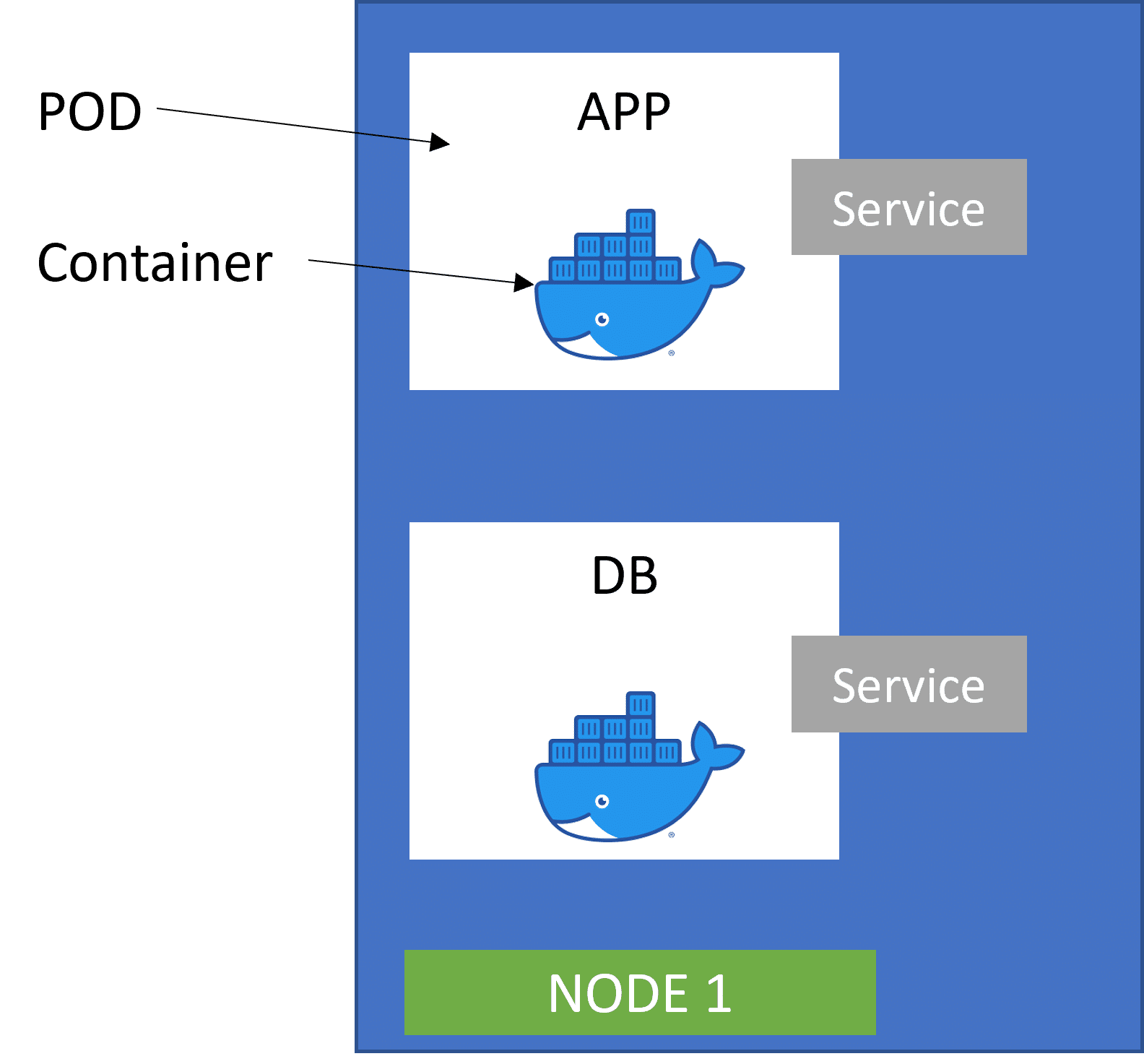
2. Service and Ingress
Service is a static IP address that is attached to each pod. The good thing is that the POD and the service recycles are not connected. In the event of a pod failure, if a new IP gets assigned to a new backup pod, the end-user service is still bound to fail because they are not aware of the new IP address. Replacing the IP with service ensures that when a new pod with a new IP is assigned to the service, the communication is still intact with other pods.
We have covered service in just a few words, but the actual functionality of the service is quite large. Read what service mesh is.
Today, most applications are browser-based to allow for the flexibility of use from any operating system. To enable browser access, we need to enable an external service that enables communication from an external source. But for security reasons, we don’t want the external source to see all of our data like the database. The information should be visible on a need-to-know basis. This is achieved by a service called Ingress. It also simplifies the destination address with HTTPS protocol.
for Example the destination address without ingress will be : http://<IP>:<Port no>. but with Ingress the desintation addrress will be : https://mynewapplication.com.
Ingress allows the external requests to go through it and then forward the requests based on request and security protocols.

3. ConfigMaps and Secrets
A ConfigMap is an API object used to store non-confidential data. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume.
A ConfigMap allows you to decouple environment-specific configuration from container images so that your applications are easily portable. Think of a situation where a tester is testing the application with the database running on his or her local system. But once the application is pushed to production, it should not be accessing the hardcoded database location on the test environment. A ConfigMap resolves this issue.
A secret is just like a ConfigMap, but it is used to store secret data like credentials in a base 64 encoded format. This ensures that all security standards are met. This is not enabled by default, as ConfigMap can store credentials in an unsecured format.
Below is an example of ConfigMap.
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
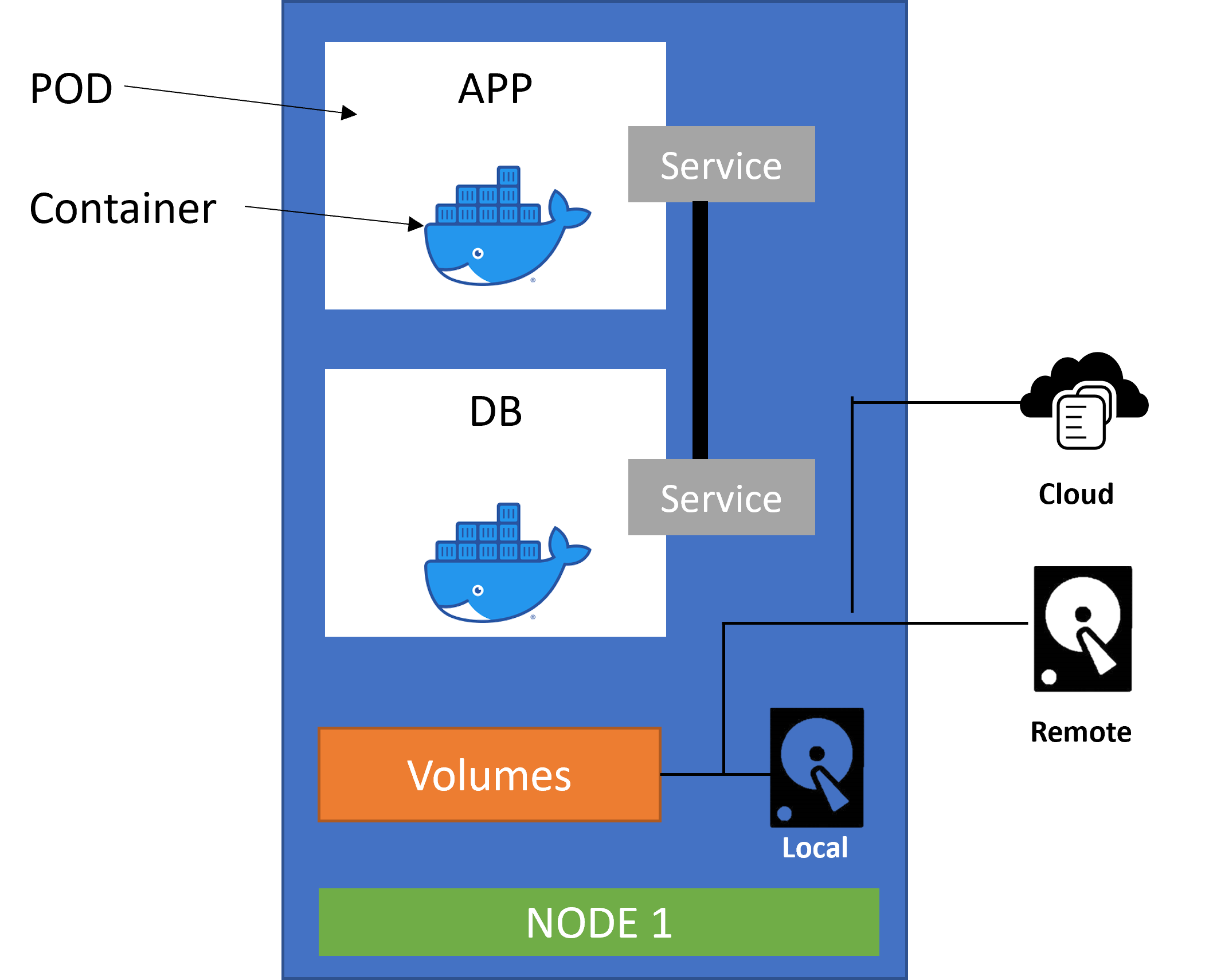
4. Volumes
Data is of utmost importance and loss of data will lead to huge cost and stability implications for the application. In the event of a DB restart, the data will be lost. To preserve all data from DB or from monitoring agents, Kubernetes uses volumes.
Kubernetes attaches physical storage on a hard drive to the pod. Kubernetes can manage the storage in any type of place, be it on a different node, server, cloud, on-premise, or on the same server.
Kubernetes by itself does not manage the persistence of the data. So the administrator is fully responsible for managing this data.
5. Deployment and Stateful set
Deployment ensures that, in case of a pod failure, a replica of the crashed pod is set up to ensure business continuity. But with distributed systems, we can ensure that such issues have very minimal downtime. Within seconds, the deployment service can recreate a clone from the blueprint of the crashed pod and link it with the existing service to ensure communications are restored and are correct.
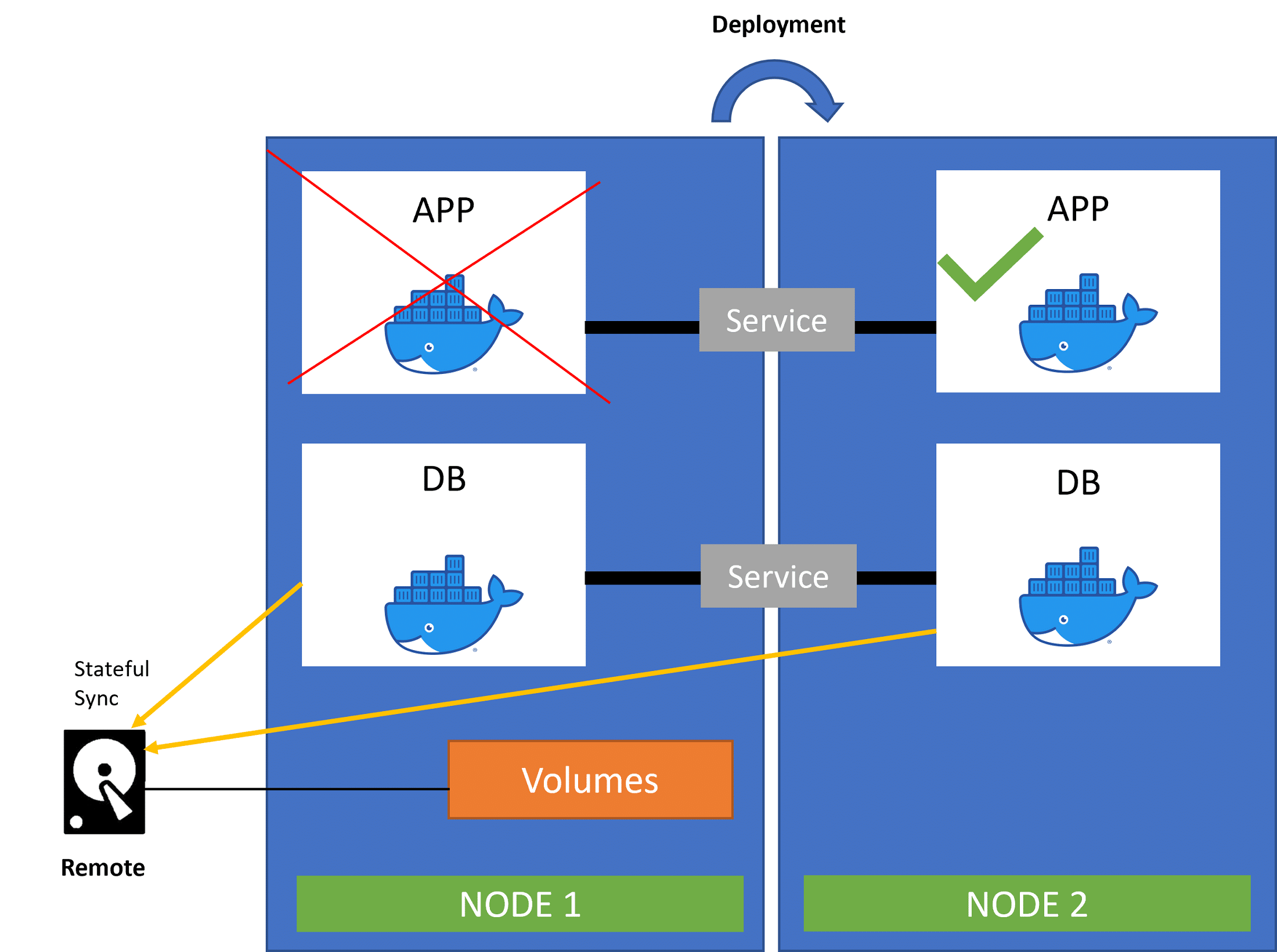
This can act as a load balancer as well to divert extra traffic to the newly cloned server so that the end-user performance is not impacted.
Deployment works well for stateless applications. It will not work well for stateful applications where databases are involved. Database pods can not be replicated because the database has a state. It is a stateful DB because it has data. The data is continuously being updated. Any cloned database must have the same synced data for the application to run smoothly after either a reboot or a rollback. We achieve this by having the DB pods store data in the same data storage. Kubernetes has a mechanism that manages which pods are currently writing to the storage and which pods are reading from it. This is done to rule out data inconsistencies while replicating. This mechanism is called the stateful set.
A simple example to explain stateful : Consider you are working on a collaborative document. You lose the internet connection. The next time you log in the collaborative document should display the latest file, not the one where you got disconnected. We achieve this by enabling stateful set.

Summary
Kubernetes is a powerful container orchestrator. Just by using these fundamental features, one can build strong Stateful applications.
- Pods and the services are used to communicate between the components.
- Ingress is used to route traffic into the Kubernetes cluster.
- external configuration is performed using ConfigMap, Secrets.
- Stateful set enables data persistence using volumes
- pod blueprints help in replicating during deployment.
Advantages and Disadvantages of using Kubernetes
- Kubernetes Ecosystem improves Productivity
- Cloud Native and can be used to deploy into multiple clouds
- Future Proof
- Makes application much more stable decentralized
- Agile than other architectures
- Overkill when used to deploy for small scale applications
- Complex product and higher learning curve for resources
- Unabetted of Kubernetes component will lead to high cost of management
- Requires a cultural shift.
0 Comments