
What is GitOps?
GitOps is a set of best practives and principles that treats version control systems, such as Git, GitHub, GitLab, BitBucket, as the central repository or single-source-of-truth to store code declaratively and then use it for deployment.
GitOps methodology is centered around the Kubernetes application. It is becoming an increasingly common practice among the high performance IT organizations to use version control like Git for infrastructure management and automation of code deployments.
For e.g., you can store information like documentation, application code, infrastructure code, and configuration files around Kubernetes deployment and then use orchestration to deploy changes to the cluster automatically.
By using GitOps, developers can now independently deploy their application into Kubernetes without understanding Kubernetes infrastructure. That means the moment a developer merges a request in Git; the deployment process would take place. In theory, a Kubernetes operator would observe the divergence between new changes ( or called the desired state) and actual clusters. An automated pipeline would be started to perform build, test, and store the artifacts in the repo. And a Kubernetes reconciler will try to sync up the running cluster with the desired definition.

Characteristics of GitOps are:
- GitOps is a methodology to achieve faster deployment into containers
- Version control is the heart of GitOps.
- To use GitOps, the entire delivery process is defined declaratively
- Once a change is approved and merged, it automatically gets reflected in the target environment.
Why is GitOps used?
To improve visibility and auditability
As all the changes go through Git, all the changes and deployments are stored and visible. So stakeholders know what is happening in the system from a software development and infrastructure-as-code perspective. If something goes wrong in the production or release process, it is easy to audit and find who made what changes.
To perform faster software delivery
Git repo can be leveraged for version control systems, peer-reviewing systems, automating and deploying processes for the production environment.
When a developer performs a code commit, he doesn’t have to depend on anyone to deploy his code into Kubernetes clusters. Using webhooks, Git can trigger a deployment pipeline automatically and push the new configuration or app changes into dev, test, or production environment.

Before understanding the working model, let us first quickly see the working principle of GitOPs ( sources: Weaveworks)
Working principles to remember while implementing GitOps
1. Declarative Language:
With Gitops, you should configure your end application and infrastructure through declarative language. Declarative languages are very high-level programming languages in which a program specifies what is to be done rather than how to do it. When your application is versioned in Git declaratively, you are maintaining a single source of truth. And this is easy for deploying into containers managed by Kubernetes. Moreover, you can create any number of replicas of Kubernetes pods using a declarative language.
2. Versioning:
With the version system, you will always have a single place to deploy from. The most significant advantage is you can roll back to your previous application state in case of any issue.
3. Automation:
Approved changes need to be automatically applied to the system. Once the application is stored declaratively in Git, one must have automation to apply any changes made in Git to production.
The best part is you don’t need any credentials to make a change into a cluster. The automation tools can onboard your Kubernetes account or namespace and can initiate deployments..
4. Assurance:
Agents like Argo CD can constantly monitor Git and notify whenever there is a mismatch in the state of Git repo and what is running in the production. These agents also ensure your entire system is self-healing, i.e., in case of failure, pods can be restarted using config files. Due to these self-healing features, you can be assured nodes or pods can be made up by Kubernetes and any potential human error can be avoided.
How does GitOps work?
Developers are assigned to write code or business logic and push it to different environments like dev, test, and production. Ideally, they will write a pull request in Git and then push all the code and merge a pull request onto the main branch.
Now, let’s say you have three environments, namely development test and production, and each of these branches maps to respective Kubernetes clusters or namespaces.
Once you push the changes onto that particular branch, there will be a relevant automated pipeline responsible for taking the code to production. This means that whenever there is a code commit for that specific branch pipeline process, the pipeline would then help test and verify if the software is apt for release. If a developer merges a development branch, and once it succeeds, they will eventually perform pull requests to incorporate the changes into the production branch.
After the merge request, the changes will get deployed into the production environment. If there is a rollback requirement, you can create another pull request to roll back to the previous state.
GitOps style delivery for Kubernetes will look something like the below:
When a user goes and changes the code in the Git repository, it creates a container image, and a container image is pushed to the container registry, which is eventually updated into config update.
Once you create a pull request to merge to a different branch, i.e., when code commit is done, the pipeline tests whether these are good-fit for the individual test cases.
This is how GitOps helps teams and solves automation problems.
Thus, GitOps can be summarized as these two things:
A path towards a developer experience for managed locations where end-to-end CI/CD pipelines get workflows applied to both operations and development.
An operating model for Kubernetes and other technologies, providing a set of best practices that unified deployment, management, and monitoring for containerized clusters and applications.
OpsMx Enterprise for Spinnaker (OES) helps you to achieve GitOps. OES is highly scalable and secures a multicloud continuous delivery platform to release software faster and frequently.
Now, let’s find out how?
Implement GitOps using OpsMx Enterprise for Spinnaker
Let’s say you have stored all of your YAML files and other documents necessary for Kubernetes deployments in the Git repository. You would require a release orchestration tool to automate the deployment process.
Now OES can help you to automate the deployment of your Kubernetes application. So once your merge request in Git repo is complete, the OES pipeline is triggered from Git using webhooks.
( and yes, we are building an operator too to find any out of sync status and take your code to production)
The pipeline would then run the following stages: build, test, deploy, verify and release, in sequence.
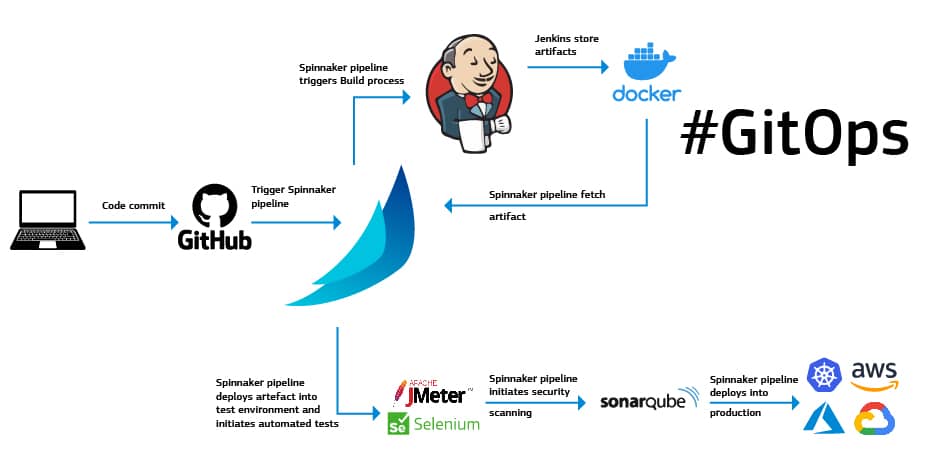
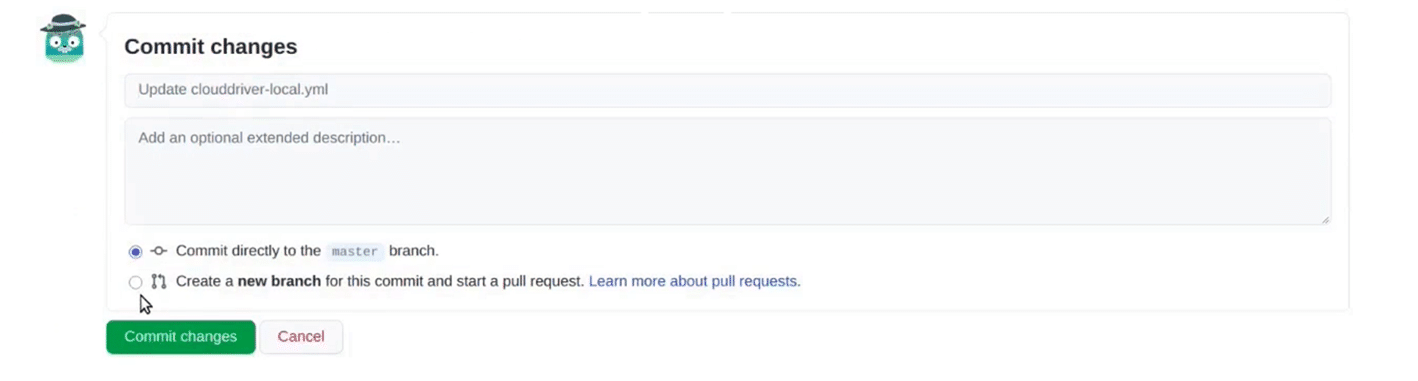
1. Code Commit Stage:
In this stage, the developer needs to create a new pull request. He can perform necessary modifications and merge the pull request with the master branch. Once the merge is complete, the SCM can trigger events- calling OES pipeline through webhooks.
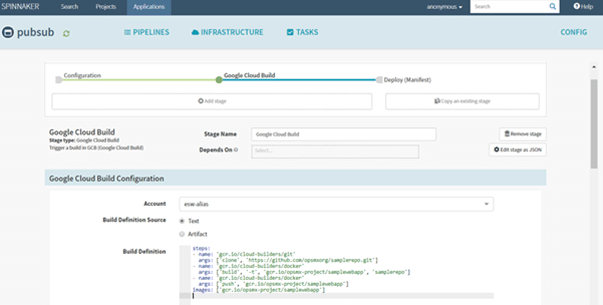
2. Build Stage
OES pipeline will execute the first stage called Build. The pipeline would trigger a building job in (say) Jenkins or Google Cloud Build. The build job would ideally be configured to fetch the configuration files (YAML files) from a particular path in Git. Once the build process is complete, the build job will generate and push a deployable artifact into a repository like Docker Hub or JFrog Artifactory.
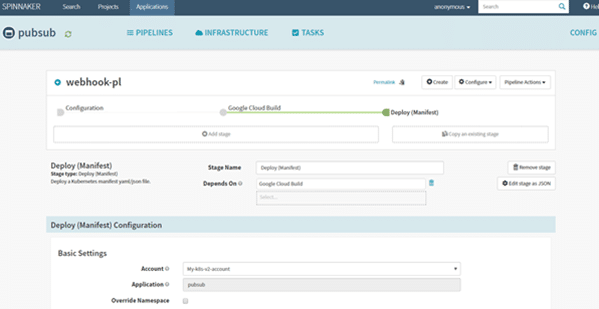
3. Deploy:
In the deploy stage, you can bake the artifact and Kubernetes resources/manifest for the deployment. You can add more stages like testing, security scanning, policy checks into the stage.
4. Kubernetes Cluster Health:
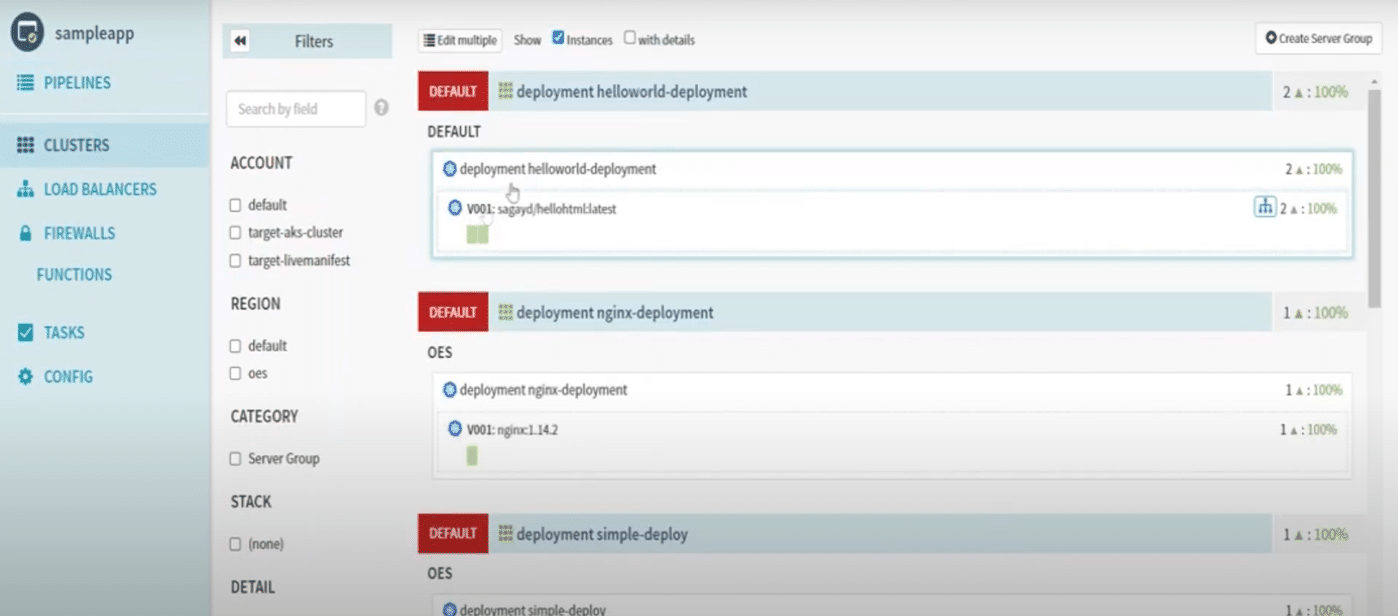
After achieving the desired state, in the post-deployment stage Spinnaker provides the information such as health of the Kubernetes clusters, number of running pods, status of load balancers etc.. So your development team doesn’t have to do kubectl -apply to check the status.
Beyond GitOps
Once the changes are deployed into the Kubernetes cluster and the desired state is achieved, the GitOps cycle ends. Even when the desired state is running, there can be unexpected performance and abnormal software behavior. And you end up raising L0 incidents or, at worst, rolling back to the previous version.
Hence we propose enforcing compliance and verification gates in your pipeline as a crucial element to ensure quality software is released and production is risk-free.
OpsMx Enterprise for Spinnaker(OES) offers data and intelligence modules to enforce policy and security checks at every pipeline stage. It also provides deployment and production verification to highlight the performance and quality regression of a release by analyzing logs and metrics from the monitoring solution.

About OpsMx
Founded with the vision of “delivering software without human intervention,” OpsMx enables customers to transform and automate their software delivery processes. OpsMx builds on open-source Spinnaker and Argo with services and software that helps DevOps teams SHIP BETTER SOFTWARE FASTER.
0 Comments